OpenSource tooling that delivered value for a Dutch Retailer
Introduction
WiseAnalytics has been contracted to help develop the data platforms of a large retailer headquartered in the Netherlands. The client was in the process of migrating their data platform from Azure to Google Cloud. The company is composed of 40 different operating companies each with their own IT systems, acquired through a series of merger and acquisitions.
An Open source powered cloud data platform
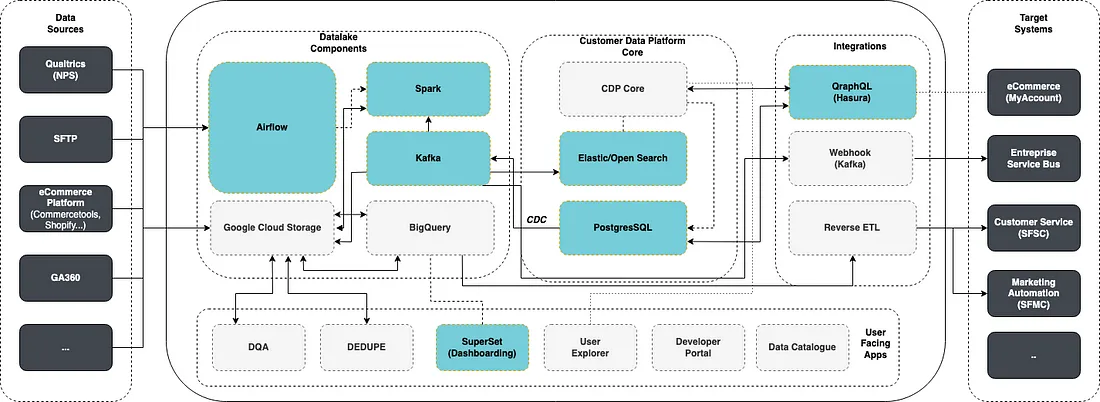
The company was attempting to scale a Global Datalake and Customer Data Platform. The team at WiseAnalytics focused on leveraging as OpenSource components to enable the development of these data platforms and their use cases.
We leveraged 7 different open source components as part of this implementation:
- Airflow — An ETL Orchestration
- Spark — A big data computation framework
- Kafka — A messaging Service
- Elastic/Open Search — A Search Engine
- PostgresSQL — An Relational Database
- Hasura — A Data API Platform
- Superset — A dash boarding solution
Benefits of open source
Leveraging open source components provided with a variety of advantages. It allows for:
- Fast time to market as it can help avoid endless procurement approval processes and allow to deliver value now
- No Vendor lock-in. Most open source tools are offered in some ways as managed services from providers like Google, or by specific vendors supporting the Open Source tooling — but they can as well be directly implemented on any cloud.
- Typically Lower operating costs — SaaS versions of open source tooling competes with the option of hosting the open source version on one’s own cloud, leading to competitive pricing for these solutions.
Deliver Value Now
Leveraging Open Source components helps speed up significantly the development process. It allows developers to run their own versions of the component either locally or in a development, without having to wait for a procurement process to finish, or even to deploy a self hosted version on production. In large organizations, budgetary and procurement processes can take a large amount time and open source versions provide a way to show value at a faster pace, even if in the end the organization wants to go for a manage solution longer term.
Vendor Lock-in
As part of the migration from Azure to GCP, we needed to migrate a number of Cloud specific technologies such as CosmosDB, Azure Service Bus or DataFactory and instead provide the client with a solution that could be ported over to a different cloud with minimal impact should they so chooses.
Lower Operating Cost
Due to the lack of vendor lock in, the healthy competition coming from the option of self hosting the open source versions, and lower development costs due to open source contributors. Prices for open source toolings and components are traditionally lower than their proprietary counterparts. Our client had been hit in the past by severe inflation of other SaaS and PaaS service and wanted to be in a better place budget wise.
Leveraging Open Source components
Spark
Spark is nowadays the de-facto processing engine for datalakes, we use it to run ETL pipelines, perform data quality assurance (DQA) and generate what we called “derived properties” — customer level metrics computed out of the raw data we received from the different operating companies. Some of the client’s data sources grew quite large, notably their clickstream data from all of their brands and e-commerce website and required a processing engine that could compute that mass of data in a cost effective manner.
Spark provided us with the means to write easily testable and extendable code that can scale with the data.
Airflow
We setup Airflow on GCP (Cloud Composer) to schedule and orchestrate the different ETL pipelines coming to and from the client’s data ecosystem as well as the transformation jobs such as the derived properties jobs.
We used Airflow’s orchestration tooling for data integration, calling different APIs such as Google’s Double Click, Facebook Marketing, Qualtrics, integrating from SFTP sources or feeding data back towards CRM and Marketing Automation systems or towards the operating companies.
SuperSet
Superset provided us with a user friendly way to give access to underlying data and create dashboards. We used it to give some self service capabilities to the different operating companies to queries and visualize their own data.
Kafka
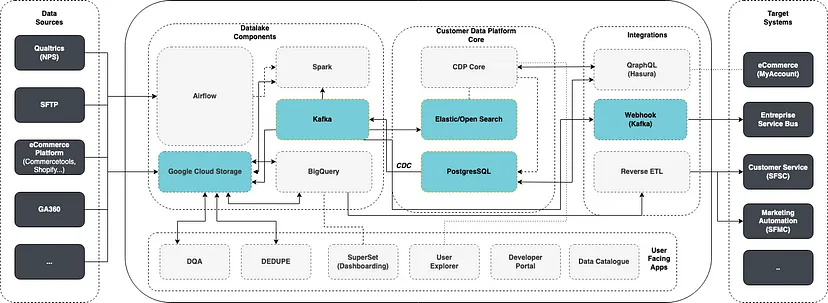
Kafka Integration Ecosystem
We used Kafka (Confluent) alongside Debezium for it’s CDC capabilities. Debezium reads data from Postgres’s replication logs and pushes them towards Kafka. We leveraged 3 different Kafka connectors to then sink the data in different parts of our platform 1) to Google Cloud Storage 2) To Elastic / Open Search 3) as Webhooks.
Hasura
The eCommerce team of the client wanted to interact with the customer data platform. We leveraged Hasura to provide GraphQL capabilities at a low development cost. Hasura can build a ready made GQL API out of database tables and connect to existing APIs for more advanced implementations.
Elastic / Open Search
Elastic Search/Open Search provided us with search engine capabilities as part the Core of the Customer Data Platform we were developing and allowed us to query customer profiles by any attributes contained within their profile. We leveraged a Kafka Sink in UPSERT mode to keep profiles updated at all times.
Postgres
We leveraged Postgres as the central piece of the CDP core. Postgres is an open source RDBMS providing ACID guarantees, while at the same time supporting multiple extension (e.g. Citus) to scale across multiple nodes and being familiar to most developer. It is as well offered in managed service form across cloud providers.